CroPyDB
Crop phenomics requires the handling of large datasets which are being decomposed from massive raw data (such as hyperspectral images or point clouds of terrestrial laser scanners) to derive a final crop model predicting the targeted trait (mostly yield and its stability). Between these two ends, a range of different modelling steps is necessary. Typically, there is a need to train feature extraction models using ground truth, correct for design factors and spatial trends in the field, derive parameters from repeated measures (e.g. growth dynamics) and model the response to environmental covariates. Finally, there is the need to combine multiple traits derived from different sensors at different year-sites into a genetic crop model to support the selection of genotypes or markers. Without proper data handling this workflow in impossible to accomplish.
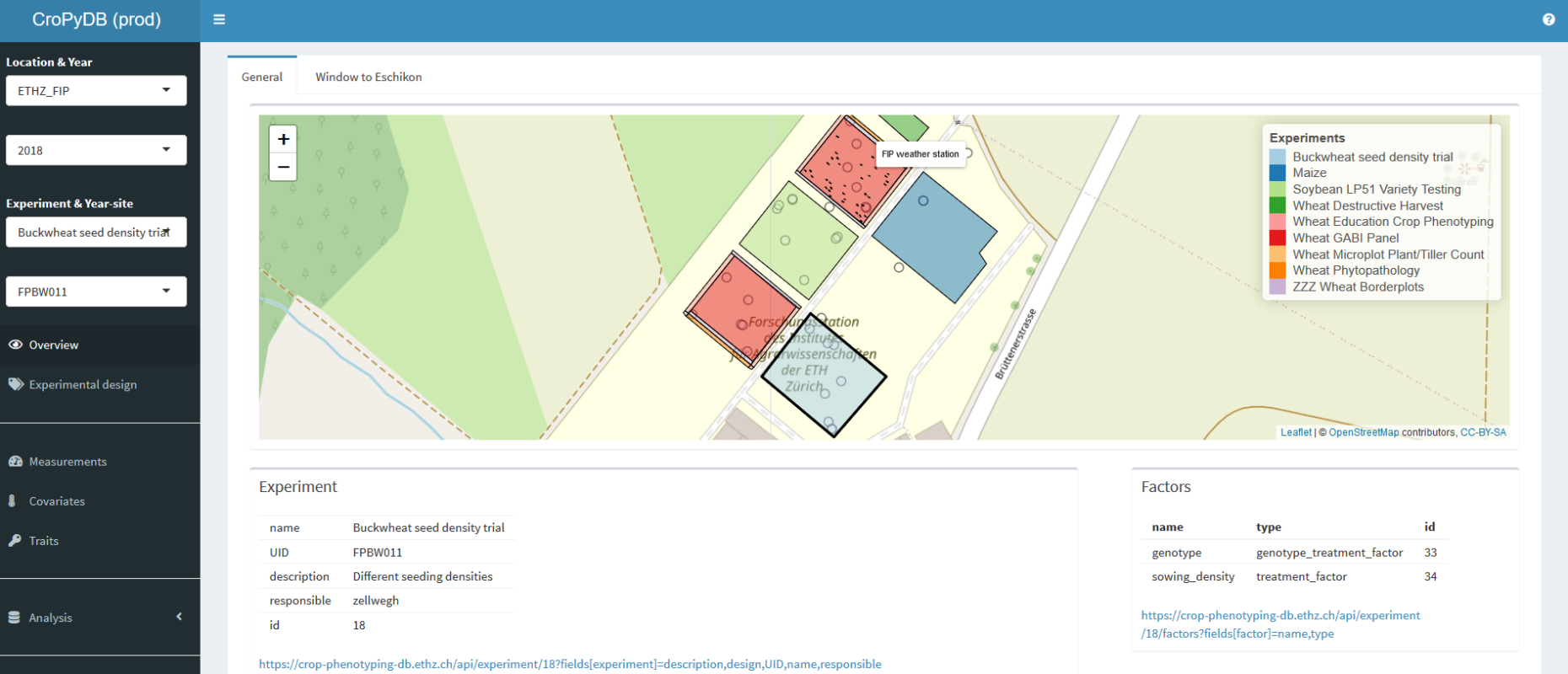
CroPyDB is being developed by the group of Crop Science to support data management in crop phenotyping and physiological breeding. It is written in external pagePython 3.6 and based on a `external pagePostgreSQL database with the spatial data extension external pagePostGIS. Crucial modules include external pageSQLAlchemy as external pageObject-relational mapper and external pageFlask-Restless as external pageJSON-API external pageREST Server.
CroPyDB has two main aims:
- Support the collection and processing of phenomics data in our research group
- Ensure compatibility of our research data to standards in plant phenomics
Therefore, we ensured that the design of CroPyDB respects the requirements of external pageMIAPPE, links to the external pagecrop ontology and uses the external pageFAO standard on multi passport data.
Contact
Professur für Kulturpflanzenwiss.
Universitätstrasse 2
8092
Zürich
Switzerland